Posts tagged machine-learning
Finding misspelled names with dirty_cat and unsupervised learning
- 13 November 2021
As a data scientist one often wants to group or analyze data conditional on a categorical variable.
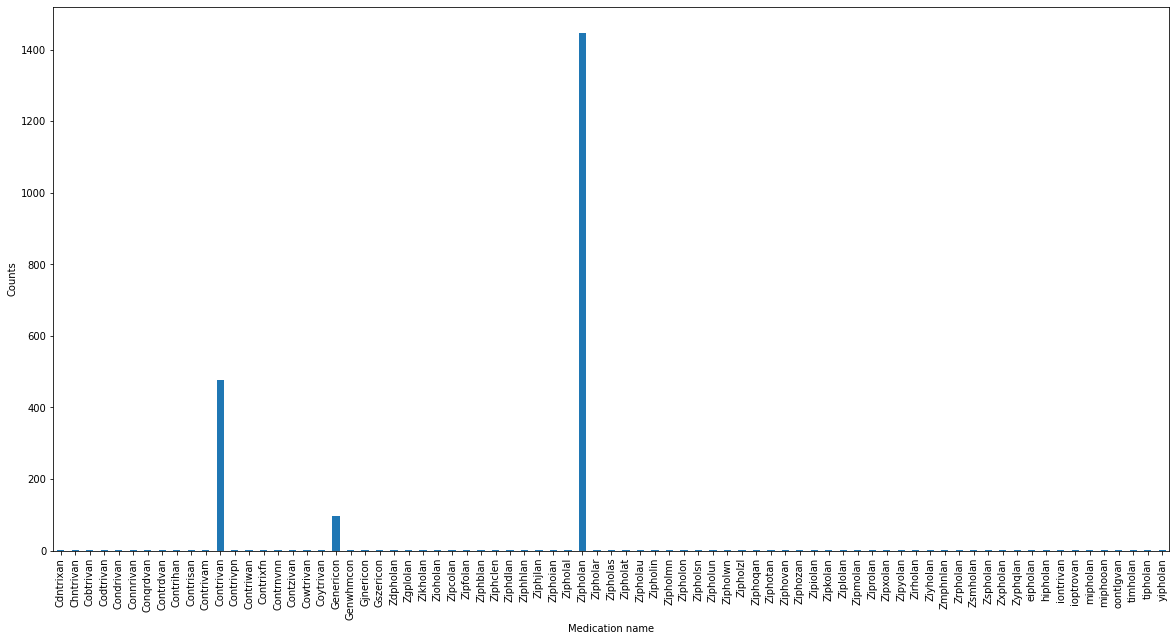
However, outside the world of neatly curated data sets, I often encounter the case that there can be slight misspellings in the category names: This happens when, for example, data input should use a drop down menu, but users are forced to input the category name by hand. Misspellings happen and analyzing the resulting data using a simple GROUP BY is not possible anymore.
This problem is however the perfect use case of unsupervised learning, a category of various statical methods that find structure in data without providing explicit labels/categories of the data a-priori. Specifically clustering of the distance between strings can be used to find clusters of strings that are similar to each other (e.g. differ only by a misspelling) and hence gives us an easy tool to flag potentially misspelled category names in an unsupervised manner.
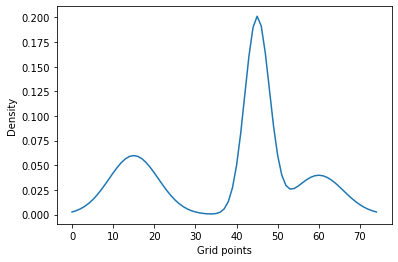
Probability density fitting of a Mixture of Gaussians via autograd
- 17 January 2020
Recently I’ve had to fit a Mixture of Gaussians to a target density instead of individual samples drawn from this density. Googling revealed that at least one other person faced this particular problem too, but there was no code readily available.
To be clear, the problem is the following: given a mixture of Gaussian probability density that is evaluated at $N$ points, we want to recover parameters of these Gaussians (i.e. mean $\mu_{i}$, standard deviation $\sigma_{i}$, and a set of mixture weights $\pi_{i}$ that are constrained to be [0, 1] and sum to 1).