Moritz Boos#
Data Scientist and former Cognitive Computational Neuroscientist
I’m a data scientist and former computational cognitive neuroscientist. I’m interested in various kinds of machine learning applications but have focused mostly on natural language processing and speech recognition. I’ve also worked on Bayesian hierarchical models in a scientific context and am always keen to add a probabilistic twist to whatever I’m working on.
During my PhD I used machine learning to understand speech processing in the brain better; specifically, I focused on the potential of probabilistic unsupervised learning and interpretable deep neural networks to predict brain activity.
Quick Links#
Recent posts and snippets about Python, machine learning, and neuroscience
Academic publications and preprints
Open source projects and tools
Recent Posts#
16 December - TIL: Making a seaborn count plot with hue and labels
It’s surprisingly hard to label bars in a seaborn countplot, especially if you use more than one column (e.g. when using
hue). The function below does the labeling even when using two columns for indexing.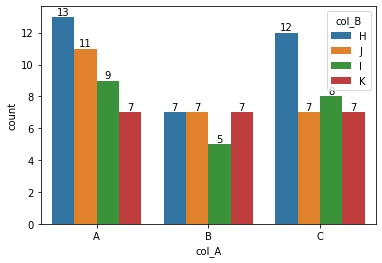
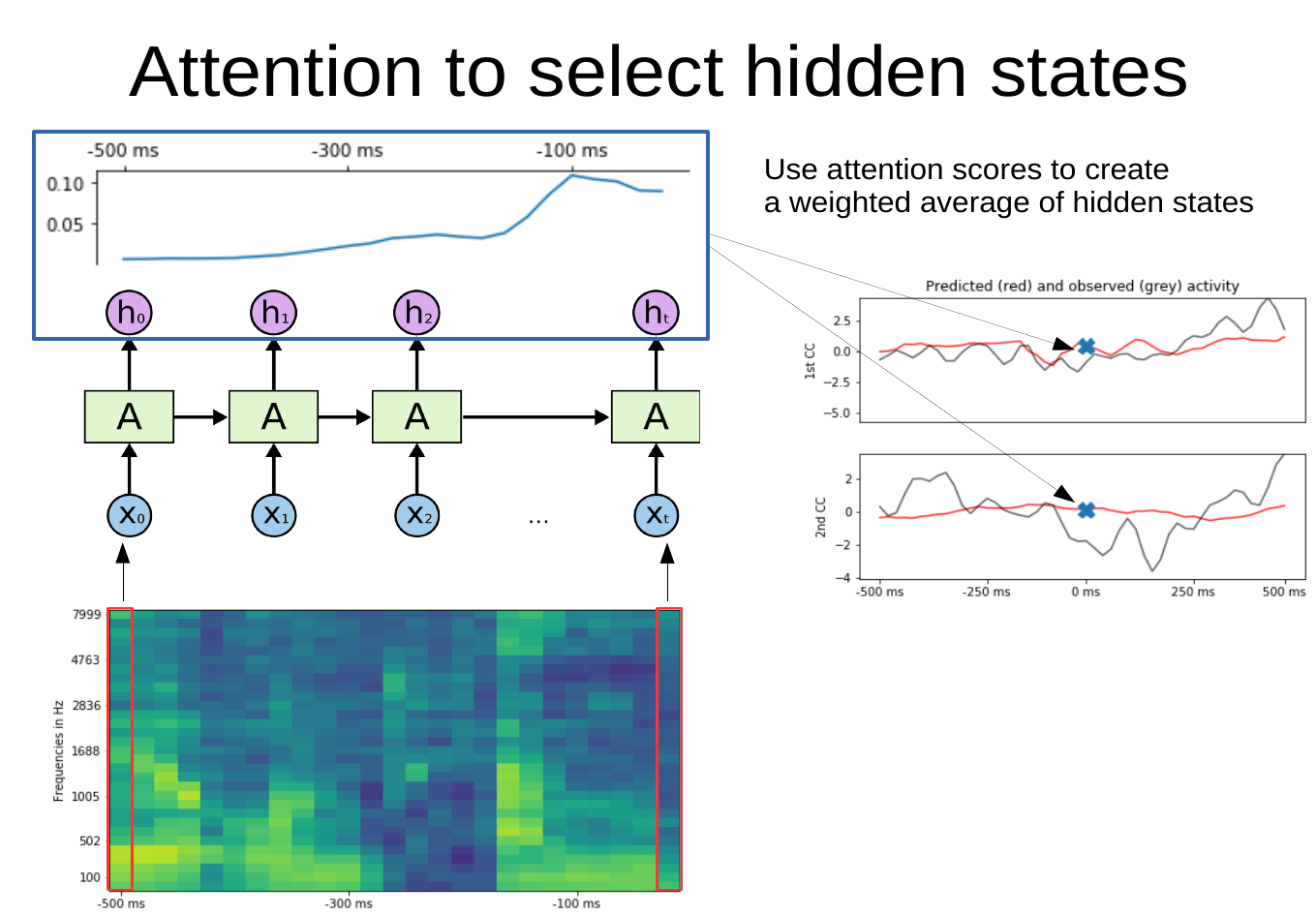
27 July - Deep auditory encoding model with self-attention to predict brain activity
Do you like deep learning-based auditory encoding models? Always wanted to train a deep recurrent model to predict brain activity from an auditory stimulus (i.e. spectrogram) but vanilla GRU/LSTM/RNN immediately overfit? Do you also care about which parts of the auditory stimulus matter most for predicting brain activity?
This library allows you to train a recurrent DNN (a GRU) and learn a self-attention mechanism that weighs hidden states - the resulting weighted tensor is used to predict brain activity (or whatever you choose as a target). It also contains many variations of this model type (shared attention between targets, multi-head attention etc) and some functions for visualizing the computed attention weights on a spectrogram.
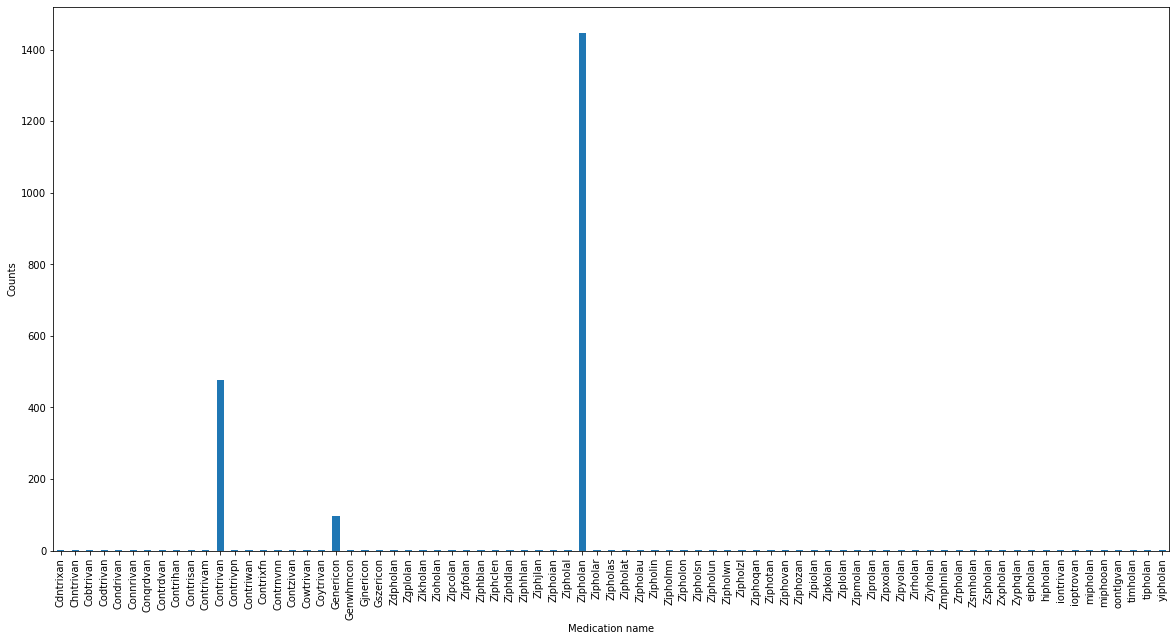
13 November - Finding misspelled names with dirty_cat and unsupervised learning
As a data scientist one often wants to group or analyze data conditional on a categorical variable. However, outside the world of neatly curated data sets, I often encounter the case that there can be slight misspellings in the category names: This happens when, for example, data input should use a drop down menu, but users are forced to input the category name by hand. Misspellings happen and analyzing the resulting data using a simple
GROUP BYis not possible anymore.This problem is however the perfect use case of unsupervised learning, a category of various statical methods that find structure in data without providing explicit labels/categories of the data a-priori. Specifically clustering of the distance between strings can be used to find clusters of strings that are similar to each other (e.g. differ only by a misspelling) and hence gives us an easy tool to flag potentially misspelled category names in an unsupervised manner.